
デザイン会社 btrax > Freshtrax > 生成AIを支えるテクノロジー【...
生成AIを支えるテクノロジー【生成AI Vol. 3】
*本記事では2024年1月現在の情報をお伝えしています。
これまで「生成AI 」シリーズのFreshtraxでは、生成AIの基本(Vol.1)とプロンプト(Vol.2)に関してできるだけ分かりやすくまとめてきた。
今回はVol.3として、生成AIのその “裏” にあるテクノロジーに焦点を当て、なぜ生成AIでこんなにも凄いことが実現できているかの謎に迫りたいと思う。
もちろんその背景には数多くのテクノロジーが複雑に絡み合っているが、今回の趣旨はできるだけわかりやすく説明することなので、焦点を絞って基本的な部分だけを抽出した。
よく聞く”LLM”とは
さて、生成AIのテクノロジーと聞いて真っ先に思いつくのが “LLM” と言う単語。ニュースやSNSでもAIとセットのように語られることが多い。
LLMとはLarge Language Modelsの略。

LLMはLarge Language Models
日本語で簡単に表現すると、たくさんの言語データを集積した「かたまり」のようなものとでも言えるだろう。
LLMは何をしてくれるの?
膨大な言語データを集めたモデルの主な役割としては、
リサーチ (Research)、分析 (Analyze)、翻訳 (Translate)、予想 (Predict)、変換 (Transform) である。
一言で表現するとLLMは生成AIが動くためのコアの部分、すなわちエンジンのようなものである。

LLMは生成系AIが動くためのエンジン
LLMはどんな企業が強いの?
では、そもそもこのLLMは、どのような企業が提供しているのか?そして、どの企業が現在のところLLMをリードしているのか?いくつかの企業の例を挙げてみよう。
・OpenAI – まずは皆さまご存知のChatGPTを提供しているOpenAI社。現在のところMicrosoftのバックアップもあり、画像やビデオを処理する能力も備えているGPT-4をリリースなどかなりリードしている。
・Google – 次に、これまた皆さまご存じのGoogle社。”Bard“と呼ばれるLLMチャットボットを保持している。Googleの膨大な世界中のデータセットにアクセスし、より広範囲のプロンプトや質問に対応できるようになっている。
また、”PaLM“というプライバシーとデータセキュリティを考慮した大規模言語モデルも開発している。
・Meta – そしてもう一社注目したいのがFacebook改めMeta社。新しいオープンソースの大規模言語モデル”LLaMA“を現在開発している。FacebookやInstagram、そしてWhatsappといった、さまざまなフォーマットのデータが多くのユーザーから集められるサービスを武器に、LLMを作り上げている。
・Technology Innovation Institute – UAEのアブダビに位置し、”Falcon“と呼ばれる複数の言語と方言をカバーし、テキストとコードの膨大な組み合わせを含む高品質のデータセットを用いてトレーニングされたLLMを開発している。
“Falcon”はHugging Face Open LLM LeaderboardでMeta “LLaMa”を上回り最高のLLMと呼ばれている。
上記の3社(OpenAI, Google, Meta)が今のところ「LLM三国志」のような感じだが、今後この勢力図も”Falcon”の事例のような新規参入を含め、どんどん変化する可能性もあるだろう。
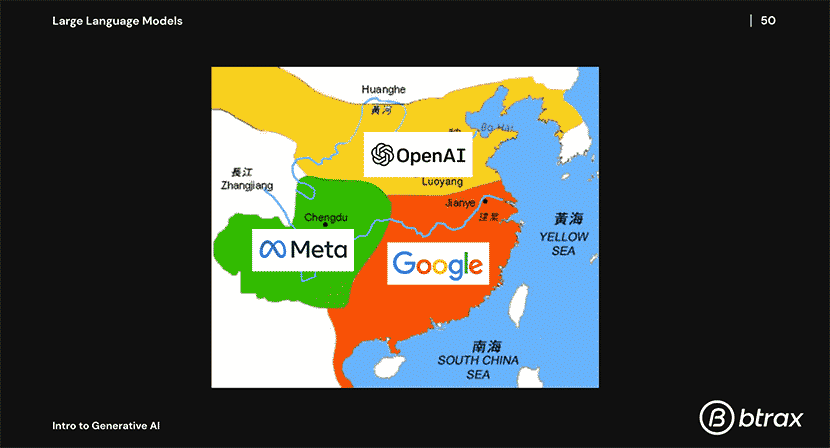
LLMは現在、OpenAi社、Google社、Meta社の「三国志」のような状態
もう一つ、トランスフォーマー
生成AIのテクノロジーを語る上でLLMに加え、もう一つ覚えておきたいのが “トランスフォーマー”と言われるもの。このトランスフォーマーの登場が現在の生成AIを格段に進化させた起爆剤にもなった。
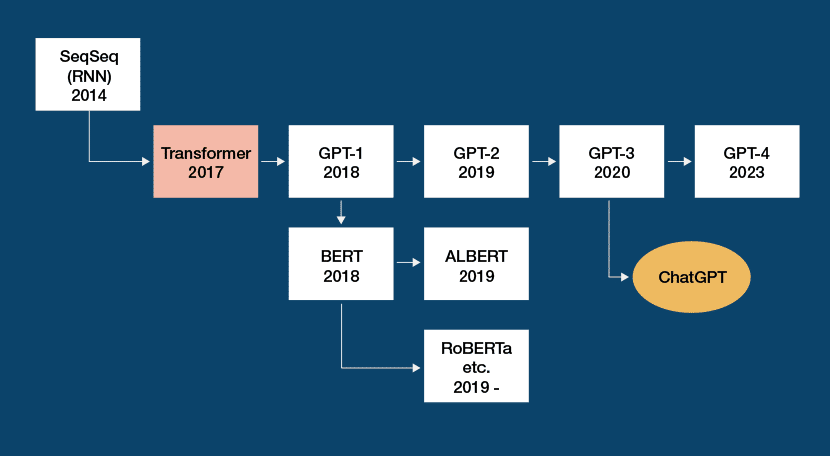
トランスフォーマーはChatGPTが生まれるきっかけにもなった
トランスフォーマーは、データを処理するための技術のひとつで、機械学習や強化学習に用いる技術のことだ。これにより、AIによる出力生成の精度が上がる。自然言語やDNAのような連続的なデータを処理するために利用される。
また、機械学習の一種である教師なし学習にも利用される。教師なし学習とは、データセットの構造を学習するために、人間がラベルをつけなくてもデータを分類し、パターンを見つけ、推奨を行うことができる手法のこと。それにより、大規模モデルの作成が簡単になりGPT2 -> 3 -> 4のように開発速度が向上した。
生成AIの裏には”LLM”と”トランスフォーマー”というテクノロジーが利用されていると考えれば、基本中の基本は抑えられているのではないだろうか。

生成AIに利用されるトランスフォーマー (これではない!)
いきなりAIサービスが急増した理由は?
生成AIに関連するサービスは日進月歩。毎週のように新しいサービスがリリースされている。
昨日できなかったことが急に今日可能になることも少なくない。それをキャッチアップするだけでも大変だ。

生成AI関連のサービス (これでもごく一部だ)
そもそもなぜ2022年後半から2023年明けにかけてこんなにも生成AIとAI関連のサービスが怒涛の発展を遂げたのか?
おそらくAI系のテクノロジーが世界の複数の場所で水面下で研究開発が進んでおり、ここ数年で一気に花開いたのであろうと考えられる。
その要因の一つが、ネット上の膨大なるデータ収集によるもの。GPT-3などは Common Crawl のデータ(世界中のWebサイト)がメインの学習元としてデータの収集を行なった。
また、テクノロジーの発展はその性質上、指数関数的に一気に進み、どこかのタイミングでビッグバンのように世の中に広がる。そして、その直前まではあまり気づかなかったりもする。
近年急激に発達したAI関連のテクノロジー
そしてもう一つの説。それはコロナ禍がAIの発展に大きく貢献したというもの。これは、Future Today InstituteのCEO, Amy Webbが提唱する説で、SXSW 2023における彼女のキーノートプレゼンテーションでも説明されていた。
皆さんも記憶に新しいと思うが、2020年初頭にパンデミックが始まった直後から仕事も学校もリモートになり、世界中がオンラインでミーティングや授業を行っていた。
そうなるとどうなるか?文字だけではなく、画像、映像、声、ロケーションなどなどのさまざまなデータが収集される。
AIはどれだけのデータを収集できるかでその精度が左右されることもあり、コロナ禍の3年で急激にデータが集まったことで、その精度がどんどん高まっていったらしい。

AIの発展にはコロナ禍が少なからず影響しているのでは (参照: Amy Webb, SXSW 2023)
今後の展開は?
こんなにも毎日急激に発展している生成AIだが、今後どのように展開して行くのだろうか?
おそらく我々が現在目の当たりにしているのはまだまだ序盤で、今後は文字や画像だけではなく、音、声、動画、そして映画などもAIによって生成されて行く可能性が高い。
そしてディープフェイクなど、さまざまな著作権、プライバシーの課題が出てくる。それに対する法整備も急ぐ必要がありそうだ。
次回は生成AIの発展が仕事に与える影響に関してまとめていく。
参考: お〜いお茶 カテキン緑茶TV-CM「未来を変えるのは、今!」篇 (生成AIによって作成されたAIタレントを起用)
 私たちと一緒に働きませんか?
私たちと一緒に働きませんか?
ビートラックスは、デザインを中心に、最適なユーザー体験を創造し、新しい価値の創出に貢献している会社です。協調性が高く、ポジティブで、主体性を持って仕事を進めるメンバーが集まっています。
私たちと一緒に働いて革新的なプロジェクトを共に実施しませんか?






